
Week 267
Disease Management, Clinical Care, Drug Discovery, Scientific Experimentation, Empirical Software
In Week #267 of the Doctor Penguin newsletter, we are sharing recent papers on LLM-based agentic systems that take on extended expert work, the first two building agents for clinical care and the last three being early AI scientist systems. We are taking a stroll through this emerging space to see how differently these systems are put together:
1. Disease Management. While large language models have shown strong diagnostic capabilities, their capacity for management reasoning, including disease progression, therapeutic response, and safe medication prescription, remains comparatively under-explored.
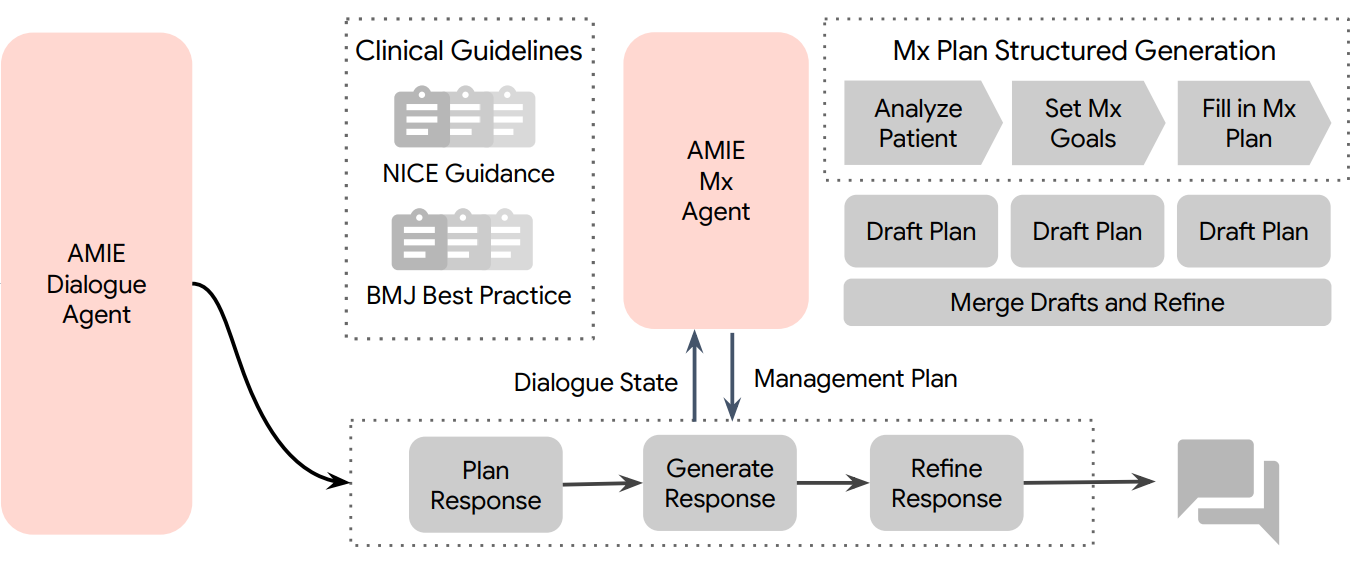
Liévin et al. developed an LLM-based agentic system optimized for multi-visit clinical management, capable of recommending investigations, treatments, and follow-up as a patient’s disease evolves across multiple encounters. The system pairs a fast Dialogue Agent that handles empathetic conversation with a slower Management Agent that retrieves around six clinical guidelines into a long-context window and explores several draft plans in parallel before merging them, with a persistent state shared by both agents carrying patient information across visits. Their design bets on long-context reasoning over a complex retrieval pipeline, and uses decoding constraints so that citations to the retrieved guidelines are generated as part of reasoning rather than added post-hoc. In a randomized, blinded virtual Objective Structured Clinical Examination study against 21 primary care physicians across 100 multi-visit scenarios, the system’s management plans were non-inferior overall, more precise in naming specific drugs, doses, and durations, and better grounded in guidelines. Notably, the ablation study challenges the necessity of scaffolding as base models improve, since off-the-shelf foundation models such as o3, GPT-5, and Gemini 2.5 Pro roughly matched the full system (built on top of Gemini 1.5 Flash). Given that patients in fragmented health systems increasingly see different clinicians across sequential visits, this study suggests conversational management agents might one day serve as a point of continuity.
Read paper | Nature
2. Clinical Care. Clinical decision-making is an inherently multi-step process in which physicians repeatedly gather patient information, reason over results, and act, nearly all of which happens inside the electronic health record (EHR) system, yet most medical AI systems read from the EHR rather than acting within it.
Ferber et al. developed MIRA, an autonomous AI agent that conducts full emergency department encounters inside a sandboxed FHIR compliant EHR server, where it elicits histories through chat with a patient agent, orders and interprets labs, imaging and microbiology, generates differential diagnoses, and executes treatment plans including prescriptions, procedures and admissions across 574 real MIMIC-IV cases spanning eight diagnoses. While prior systems either tackled isolated subtasks or offered free text advice, MIRA turns clinical intent into structured, actionable EHR operations by forcing every decision through standardized medical codes, which has the dual payoff of producing orders a real EHR would accept and of converting evaluation into clean code-level matching against the dataset and against physicians rather than subjective text judgment. MIRA also follows a physician-like, stepwise workflow from initial presentation through admission, proceeding in the usual order of care, moving from less invasive steps such as blood tests to more invasive interventions such as surgical procedures. Under identical conditions it matched or exceeded both board certified and mixed seniority physicians on diagnosis, procedure selection and guideline adherence. A robustness check further appended different patient traits (such as anxiety, a different sex, insisting they were healthy, being convinced it was cancer, or speaking only German or French), and diagnostic accuracy stayed stable across all six conditions. One caveat is that the simulated patients, grounded in discharge summary text, speak more coherently than real emergency patients and lack the disfluency and omissions of genuine history taking.
Read Paper | Nature
3. Drug Discovery. Many drug repurposing breakthroughs were logically inferable from existing literature years before they were realized, suggesting that what often holds discovery back is not missing data but the synthesis of disparate scientific knowledge.
Ghareeb et al. introduce Robin, a multi-agent system that closes the loop for experimental biology. Given a disease of interest, Robin automatically identifies relevant in vitro assays that model key disease mechanisms and proposes specific drug candidates to evaluate in these experimental models, prioritizing candidates with established safety profiles and searching for known toxicities or off-target interactions. The researchers then conducted the experiments and provided the resulting data back to Robin for autonomous analysis, which it interpreted to generate a new round of therapeutic candidates. Through this process, Robin drove an iterative therapeutics development cycle in which hypotheses were generated, tested, analyzed, and refined based on experimental results. As an initial proof-of-concept, the study applied Robin to dry age-related macular degeneration (dAMD): it proposed enhancing retinal pigment epithelium phagocytosis, nominated candidates that were tested in vitro, then analyzed those flow cytometry results to drive a second round that surfaced ripasudil, a ROCK inhibitor already clinically approved for glaucoma but never previously proposed for this disease, which outperformed the first-round hit and was validated in primary human cells. A follow-up RNA-seq experiment that Robin itself proposed then flagged ABCA1 as a possible novel target. By focusing on combinatorial synthesis, the identification of non-obvious connections between disparate fields, Robin targets low-hanging fruit that human experts may overlook due to the compartmentalization of scientific knowledge, suggesting that the bottleneck in discovery may be synthesis rather than data.
Read Paper | Nature
4. Scientific Experimentation. Existing AI research agents can run experiments but typically follow a single line of inquiry, or a division of the search space decided at the outset. This strategy may collapses in long-running science where the promising directions are not known in advance and shift as evidence accumulates.
Gao et al. introduce AutoScientists, a decentralized team of LLM agents for long-running computational experimentation that coordinates through a shared experimental state rather than a central planner. Agents read a common record of proposals, results, failures, and the current best model, then self-organize into teams around competing hypotheses, critique each other's ideas before any compute is spent, and reorganize once a direction stops paying off. The design treats exploration as a managed resource, storing failed directions in dead-end registries so teams do not rediscover the same negative result, and pushing agents toward untested parameters rather than safe incremental tweaks. One experiment makes the source of its advantage concrete. On a task of improving how a small language model is trained, both AutoScientists and a single-agent baseline started from the same setup and ran for roughly 100 attempts. The single agent improved zero times, cycling through tweaks near choices that were already optimized, while AutoScientists found seven improvements of genuinely different kinds, the first of which the single agent never even proposed. This points to a wider set of hypotheses, rather than more compute, as the likely source of the advantage, though it rests on a single run the authors are careful not to overread. They also note the system is not more token efficient, and that automatically discovered models should not be treated as biologically actionable without independent expert validation.
Read Paper | arXiv
5. Empirical Software. The cycle of scientific discovery is frequently held up by the slow, manual creation of software to support computational experiments.
Aygün et al. developed Empirical Research Assistance (ERA), a system that automatically writes empirical software to maximize a quality score. ERA works by having an LLM repeatedly rewrite a program to improve its score, while a tree search keeps a growing pool of candidate programs and decides which one to improve next, balancing refinement of strong solutions with exploration of neglected ones. Because the search can return to any earlier program rather than only building on the most recent one, it can abandon an approach that has stalled and revisit a promising idea from much earlier, mirroring the trial and error that underlies real research. Across single-cell genomics, COVID hospitalization forecasting, time series, geospatial segmentation, and neural activity prediction, ERA produced expert-level results. Rather than treating the model as a one-shot code generator, the system reframes the task as a search over research ideas, feeding summaries of published papers, outputs from research agents, and combinations of pairs of existing methods into the prompt that guides the model. This last strategy proved especially useful, with the hybrids it produced often beating both of their parent methods, and across fields the best strategies followed a clear pattern, starting from something simple like historical averages and recent trends and adding complexity only where it helped. These results show the potential of using LLMs to automate complex engineering workflows, lowering the technical barrier to sophisticated computation in a way that accelerates beneficial discovery while simultaneously easing the deployment of powerful models in sensitive domains.
Read Paper | Nature
-- Emma Chen, Pranav Rajpurkar & Eric Topol