
Week 264
Rare Disease Diagnosis, ChatGPT Health, Robotic Intraocular Surgery, LLM Moral Competence
In Week #264 of the Doctor Penguin newsletter, the following papers caught our attention:
1. Rare Disease Diagnosis. Rare diseases remain difficult to diagnose due to their clinical heterogeneity, low individual prevalence, and limited clinician familiarity. Can agentic systems help shorten the diagnostic process that currently averages more than five years, marked by repeated referrals, misdiagnoses, and unnecessary interventions?
Zhao et al. developed DeepRare, a multi-agent system for rare disease differential diagnosis. The system has three layers: a central LLM that maintains a memory bank and orchestrates the diagnostic workflow; specialized agents for tasks like symptom extraction, genetic data analysis, and similar case retrieval; and external medical knowledge sources such as PubMed, OMIM, and Orphanet. A notable design feature is a self-reflective loop that iteratively reassesses hypotheses to reduce over-diagnosis and hallucinations, revisiting earlier steps to gather more evidence if all candidate diseases are ruled out. Evaluated on nine datasets spanning 6,401 cases and 2,919 rare diseases from clinical centers across Asia, North America, and Europe, DeepRare achieved 57.18% Recall@1 on HPO-based tasks (where input is standardized symptom descriptions rather than raw clinical notes or genetic data), outperforming the second-best method by nearly 24 percentage points. On multimodal cases combining symptoms with genetic data, it reached 69.1% Recall@1 compared to 55.9% from Exomiser, a widely adopted clinical tool for rare disease diagnosis. The system also outperformed experienced rare disease physicians (64.4% vs 54.6% at Recall@1), expert review confirmed 95.4% agreement on its reasoning chains, and the agentic framework boosted raw LLM performance by roughly 28 to 30 percentage points regardless of the underlying model, suggesting its strength comes from the orchestrated workflow rather than any specific LLM.
Read paper | Nature

2. ChatGPT Health. Even if consumer-facing AI products state in disclaimers that they are not intended for diagnosis or treatment, they will still function as de facto triage tools for the millions of users who consult them.
Ramaswamy et al. stress-tested OpenAI's ChatGPT Health for triage recommendations using 60 clinician-authored vignettes across 21 clinical domains. The system performed well on intermediate-acuity cases (93% accuracy for semi-urgent, 76.9% for urgent) but struggled at clinical extremes, under-triaging 52% of true emergencies and over-triaging 65% of non-urgent cases, suggesting a central tendency bias possibly driven by underrepresentation of clinical extremes in training data. It recognized classic textbook emergencies like stroke and anaphylaxis with 0% under-triage, but failed when emergency status depended on clinical trajectory rather than snapshot presentation. For instance, in asthma exacerbation cases, it recognized warning signs like elevated CO₂ but rationalized them away, whereas no experienced clinician would delay for rising CO₂ signaling respiratory failure. Adding objective findings such as lab values and vital signs significantly reduced over-triage for non-urgent presentations but increased under-triage for emergencies. The system showed no significant demographic bias, and access barrier statements (insurance, transportation, work constraints) did not affect triage results. However, false reassurance from family and friends (e.g., "My friend said it's nothing serious") significantly shifted triage toward less urgent care in edge cases. The crisis intervention guardrail for suicidal ideation fired paradoxically, activating more reliably when patients described no specific method than when they identified one, and including normal lab results completely suppressed the guardrail despite identical clinical severity. Notably, this study used clinical vignettes rather than real-world interactions, and consumers tend to under-report symptoms and misapply advice even when guidance is correct, which would compound the triage errors reported here.
Read Paper | Nature Medicine
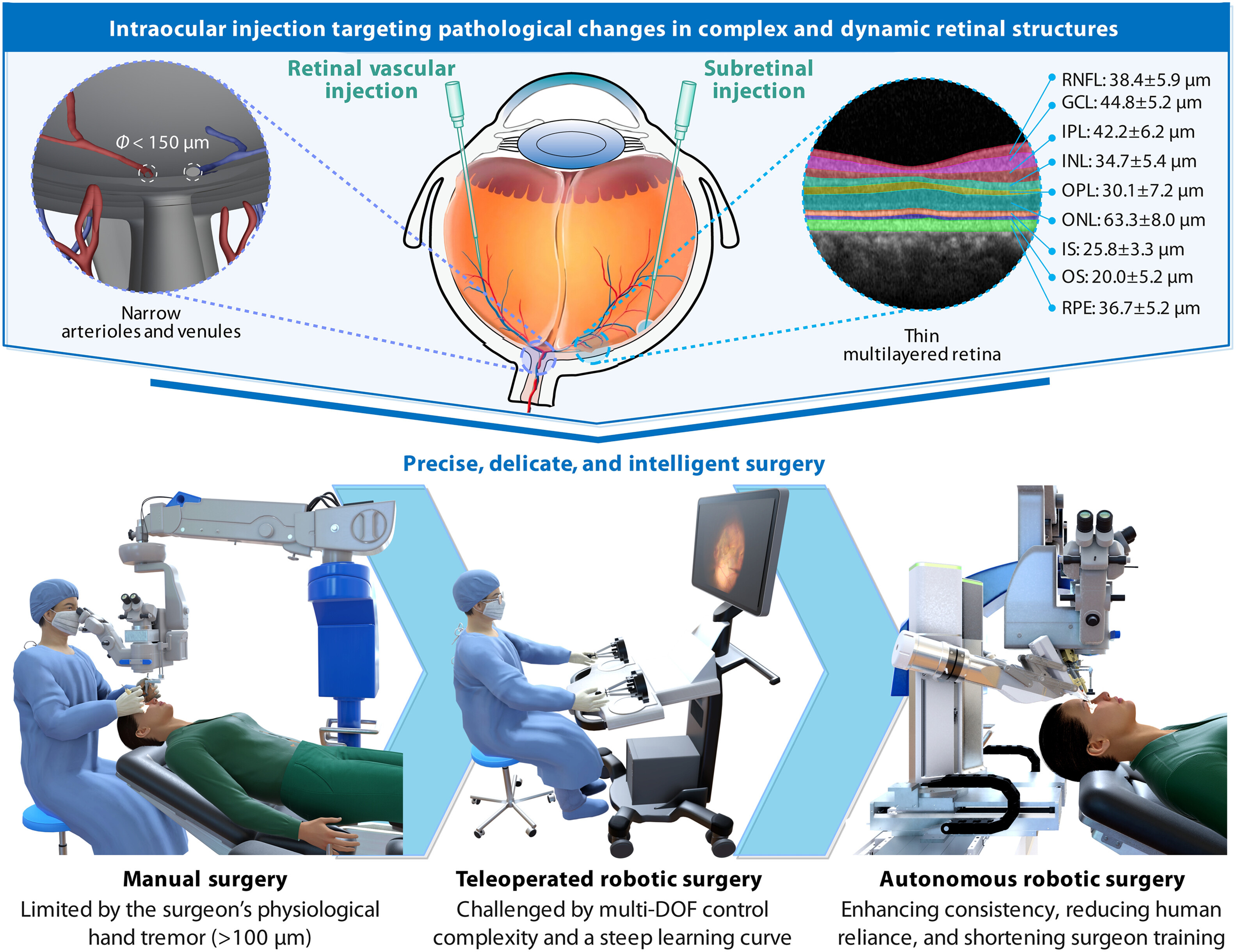
3. Robotic Intraocular Surgery. Retinal surgeries demand micrometer-level precision against targets as thin as 25 μm, yet human hand tremors exceed 100 μm, placing these procedures beyond the physiological limits of manual control.
Bian et al. developed ARISE, the first fully autonomous robotic system for targeted retinal injections in intraocular surgery. Conventional ophthalmic surgery relies primarily on surgical microscopes, which are constrained by a limited field of view and cannot reveal microstructures beneath the retinal surface. Microscope imaging is further degraded by shadows, reflections, occlusion, and lens artifacts. ARISE addresses this by fusing multiple imaging sources (surgical microscope, intraoperative OCT, preoperative OCT with fundus photography, and optical tracking) through a multiview spatial fusion framework to construct a dynamic 3D intraocular map. By tracking the needle tip in real time, the system plans trajectories for the injection needle and lighting fiber and executes the puncture with human oversight. ARISE achieves macro/micro-precision positioning of a 60-μm needle tip, validated across eyeball phantoms, ex vivo porcine eyeballs (100% success for subretinal, CRV, and BRV injections, n=20 each), and in vivo animal eyeballs (100% success, n=16 each), reducing positioning errors by ~80% and ~55% compared with manual and teleoperated surgery, respectively. Although surgeons currently perform these procedures by hand, targets like the 25-μm-thick retinal pigment epithelium and vessels under 150 μm in diameter demand precision that exceeds the physiological limits of manual control. By achieving average positioning errors of 10–20 μm, ARISE closes this gap between what the surgery requires and what human hands can deliver.
Read Paper | Science Robotics
4. LLM Moral Competence. Do large language models (LLMs) possess genuine moral competence rather than mere moral performance?
In this Perspective, Haas et al. propose a roadmap for evaluating moral competence in LLMs. They identify three core challenges: (1) the facsimile problem, where we cannot tell from outputs alone whether a model is genuinely reasoning about morality or just pattern-matching (e.g., a model may correctly solve "34 + 76" by actually adding or by recalling memorized strings, and we cannot tell which; similarly, a model asked about intergenerational sperm donation may simply apply priors about incest rather than recognizing the distinct normative structure); (2) moral multidimensionality, where moral decisions are shaped by complex interactions between moral, non-moral, and irrelevant factors that trade off in context-sensitive ways (e.g., lying to a partner is wrong unless it is for a surprise party); and (3) moral pluralism, where the authors argue that unlike humans who we consider competent when they hold firm, consistent views while respecting others' values, LLMs should be required to hold multiple sets of moral beliefs and values simultaneously, given that a few commercial models serve billions of users worldwide (e.g., "Is it OK to order steak?" should yield different acceptable answers when conditioned on Jainism, Halal dietary laws, or pescetarianism). To address these challenges, the authors advocate for adversarial, disconfirming evaluations that test models on held-out problems with altered normative structures, parametric experimental designs that systematically manipulate moral and contextual variables, and combined "Overton pluralistic" and "steerably pluralistic" approaches, while cautioning that LLMs may ultimately develop a "third kind" of moral competence distinct from both human moral cognition and mere memorization.
Read Paper | Nature
-- Emma Chen, Pranav Rajpurkar & Eric Topol