
Week 256
Robotics, Ophthalmology Foundation Model, Influenza Vaccine Strain Selection, Antibiotic Design, Agentic EHR Benchmark, Data Privacy
In Week #256 of the Doctor Penguin newsletter, the following papers caught our attention:
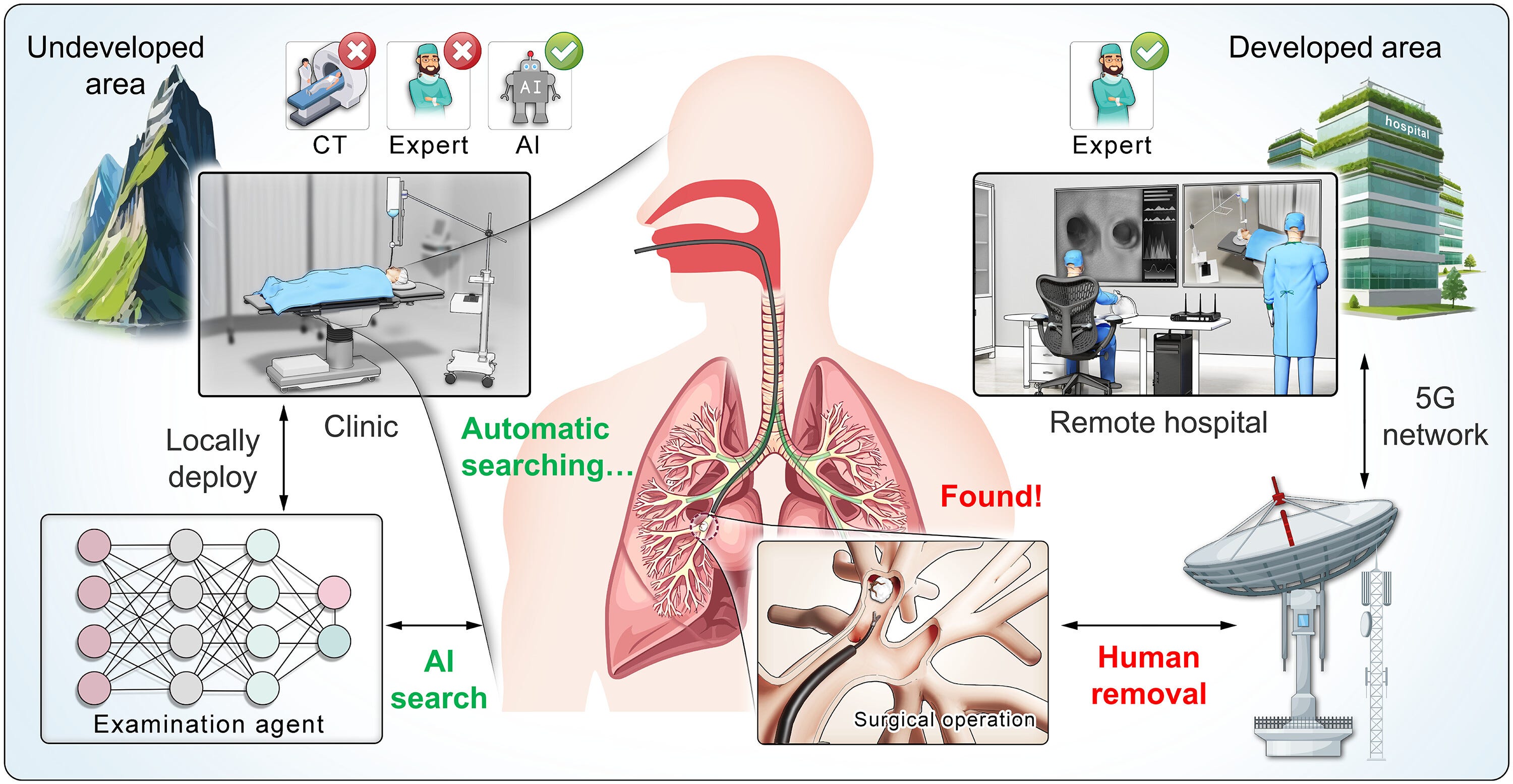
1. Robotics. Foreign body aspiration (FBA) is a life-threatening condition that occurs when an inhaled object becomes lodged in a person's airways, with the majority of cases involving objects trapped in the bronchi. Bronchoscopy remains the gold standard for both diagnosing and treating FBA. However, bronchoscopic treatment requires a thorough and systematic search through all possible bronchial pathways to locate the foreign body—a process that is both time-consuming and skill-intensive. This exploration carries a high risk of secondary injury to patients, particularly when external navigation aids such as preoperative CT imaging and surgical planning are unavailable.
Liu et al. developed a robotic bronchoscopy system that successfully performed remote surgery across 1,500 kilometers using 5G communication. This low-cost (<$5,000 USD), portable system uses only a camera sensor to autonomously navigate and search bronchial airways without requiring CT scans or external positioning systems. During surgery, the AI conducts a complete bronchial examination while a supervising physician remotely observes the process. Upon identifying a foreign body, the system alerts the remote physician, who then overrides AI control to halt the bronchoscope's advancement and operates forceps to grasp the object. Afterward, the AI resumes control and extracts the bronchoscope with the foreign body from the bronchi. Throughout this entire process, only the forceps operation requires direct physician involvement, significantly minimizing demands on expert attention and cognitive load. The AI agent incorporates two core components: a policy neural network for visual perception and robot control, and a tree-like memory bank for long-term memory storage and exploration planning. Validated through extensive simulations, phantom testing, and live pig experiments, the system achieved 100% success rates in foreign body retrieval and completed procedures in under 5 minutes compared to 42 minutes for traditional CT-guided approaches.
Read paper | Science Robotics
2. Ophthalmology Foundation Model. Current foundation models for ophthalmology mostly rely on single-modality training and lack the rigorous prospective validation needed for clinical implementation.
Wu et al. developed EyeFM, a multimodal vision-language foundation model pretrained on 14.5 million ocular images from five imaging modalities paired with clinical texts from global, multiethnic datasets. The study conducted comprehensive validation through a three-phase approach: retrospective analysis, multicountry efficacy studies with 44 ophthalmologists across North America, Europe, Asia and Africa, and ultimately a double-masked randomized controlled trial involving 668 participants and 16 ophthalmologists in China. Following a 'clinical trial' informed approach, the authors first validated model safety through performance testing, then assessed efficacy through controlled implementation with the ophthalmologists. Only after demonstrating safety and efficacy did they proceed to a randomized controlled trial measuring real-world effectiveness against standard care, followed by post-deployment interviews to gather clinician feedback for future optimization. EyeFM outperformed existing foundation models in retrospective validations, improved diagnostic and reporting performance when used by ophthalmologists in multicountry studies, and demonstrated superior clinical outcomes in the randomized trial, with ophthalmologists using the AI copilot achieving higher diagnostic accuracy, better report standardization, and improved patient compliance with treatment recommendations compared to standard care alone.
Read Paper | Nature Medicine
3. Influenza Vaccine Strain Selection. Twice a year, World Health Organization (WHO) recommends influenza vaccine strains for the upcoming seasons. After each season, influenza vaccine effectiveness is retrospectively evaluated. However, despite decades of research in prevention and surveillance, current influenza vaccines provide limited protection. For instance, during the 2014–2015 winter season, vaccine effectiveness was only 19%.
Shi et al. developed VaxSeer, an AI-based computational framework designed to improve influenza vaccine strain selection by predicting which vaccine candidates will provide the best "antigenic match" against circulating viruses in future flu seasons. The system combines two machine learning models: (1) a dominance predictor that forecasts which viral strains will be most prevalent in upcoming seasons. This predictor expresses the change in dominance over time using an ordinary differential equation, with parameters estimated by protein language models, enabling the prediction of dynamic dominance based on the entire protein sequence; and (2) an antigenicity predictor that estimates how effectively vaccine-induced antibodies will neutralize specific viral strains. Through retrospective analysis of 10 years of data (2012-2021) for influenza A/H1N1 and A/H3N2 subtypes, VaxSeer consistently selected vaccine strains with better empirical antigenic matches than the WHO's annual recommendations, with predicted coverage scores showing strong correlation with real-world vaccine effectiveness (r = 0.861) and disease burden reduction. The approach addresses a critical challenge in influenza vaccination, where current vaccines average below 40% effectiveness partly due to the difficulty of predicting which viral strains will dominate during the 6-9 month vaccine production period, offering a promising computational tool to supplement traditional laboratory-based vaccine selection processes.
Read Paper | Nature Medicine
4. Antibiotic Design. Antibiotic-resistant bacterial infections cause approximately five million deaths annually, representing an urgent public health crisis. Pathogens like Neisseria gonorrhoeae (N. gonorrhoeae) and Staphylococcus aureus (S. aureus) are classified as "urgent" and "serious" threats by the CDC. While deep learning has accelerated antibiotic discovery and identified new structural classes, current approaches are constrained by existing in silico libraries, limiting explorable structural diversity.
Krishnan et al. developed a generative AI framework that designs novel antibacterial compounds using two models: a genetic algorithm based on chemically reasonable mutations (CReM) and a variational autoencoder (VAE). Both models can operate either with chemical fragments as starting points or generate molecules entirely from scratch. When using fragments as starting points, the authors first used graph neural networks to comprehensively screen over 45 million chemical fragments in silico, identifying those predicted to have selective antibacterial activity against N. gonorrhoeae and S. aureus, then used their generative models to expand these promising fragments into complete molecules. Alternatively, their models could generate molecules de novo without any fragment input. Together, these approaches generated over 36 million previously unenumerated compounds with predicted antibacterial activity, from which 24 were synthesized and 7 empirically validated as antibacterial, including two lead compounds (NG1 and DN1) that displayed high potency, selectivity, distinct mechanisms of action from clinically used antibiotics, and efficacy in mouse infection models. While the fragment-based strategy constrains the search space to realistic, drug-like molecules when highly synthesizable fragments are chosen as starting points, the de novo approach faces the challenge of unrestricted exploration across vast chemical space without such structural guidance, yet still achieved a 27% true discovery rate among tested compounds that proved to be structurally diverse and exhibited favorable drug-like characteristics after stringent filtering for novelty, low cytotoxicity, and synthesizability.
Read Paper | Cell
5. Agentic EHR Benchmark. A virtual interactive healthcare environment to benchmark medical large language model (LLM) agents.
Jiang et al. developed MedAgentBench, a benchmark designed to evaluate the agent capabilities of LLMs in medical contexts, consisting of 300 patient-specific clinical tasks from 10 categories written by physicians, realistic profiles of 100 patients with over 700,000 data elements, and an interactive environment that simulates real electronic health record systems using FHIR APIs. The tasks span patient communication, information retrieval, data recording, test ordering, documentation, referral ordering, medication ordering, and data aggregation and analysis, requiring more than 2 steps on average for completion. The envisioned workflow operates as follows: a clinician specifies a high-level task to the agent orchestrator; the LLM agent interprets the task and plans function calls; the agent executes tasks by sending requests to the FHIR server to modify medical records; and the orchestrator provides output summarizing the completed tasks. Testing 12 state-of-the-art LLMs revealed that the best-performing model (Claude 3.5 Sonnet v2) achieved only a 69.67% success rate, with models generally performing better on query-based tasks than action-based tasks and exhibiting common error patterns including failing to follow instructions exactly (such as incorrect API request formatting) and providing full-sentence responses when only numerical values were expected. Results show that current LLMs exhibit significant performance variation across task categories and are not yet ready to function as highly reliable medical agents.
Read Paper | NEJM AI
6. Data Privacy. Generative artificial intelligence models facilitate open-data sharing by learning data distributions from private medical imaging datasets and generating synthetic data as surrogates of real patient data. However, data memorization, where models generate patient data copies instead of novel synthetic samples, could result in patient re-identification and compromise the privacy these models are designed to protect.
Dar et al. reveal a significant privacy vulnerability in latent diffusion models (LDMs) used for medical image synthesis by training them on various medical imaging datasets (MRI, CT, X-ray) and discovering that approximately 37.2% of patient data was memorized, with 68.7% of synthetic samples being patient data copies rather than truly novel images. Using a self-supervised copy detection approach based on contrastive learning, the study shows that LDMs were more susceptible to memorization than GANs and autoencoders, though LDMs produced higher-quality images. Augmentation strategies during training, small architecture size, and increasing datasets can reduce memorization, while overtraining the models can enhance it. Increasing the training data size slightly increased the number of memorized samples; however, it decreased the probability of a synthesized sample being a patient data copy. These results emphasize the importance of carefully training generative models on private medical imaging datasets and examining the synthetic data to ensure patient privacy.
Read Paper | Nature Biomedical Engineering
-- Emma Chen, Pranav Rajpurkar & Eric Topol