


In Week #250 of the Doctor Penguin newsletter, the following papers caught our attention:
1. Diagnostic Conversation. Clinical history-taking and diagnostic dialogue are fundamental to effective healthcare delivery, with physicians' conversational skills being essential for accurate diagnosis and establishing patient trust. How can AI systems be developed and evaluated to perform these complex medical conversations?
Tu et al. developed AMIE (Articulate Medical Intelligence Explorer), a PaLM 2-based AI system optimized for diagnostic medical conversations through instruction fine-tuning. One of the tasks it was trained on was dialogue generation, where the fine-tuning examples were crafted from an evolving simulated dialogue dataset generated by a four-agent framework: a patient, doctor, moderator, and critic agent to provide feedback to the doctor agent for self-improvement. To iteratively fine-tune AMIE, the system first used self-play to generate high-quality conversations based on the critic agent's feedback, then incorporated these refined simulated dialogues into subsequent fine-tuning iterations. This iterative approach allowed AMIE to improve across 5,230 different medical conditions. During actual use, AMIE employs a three-step reasoning chain that analyzes patient information, formulates appropriate responses, and refines its output for accuracy and empathy. In a randomized, double-blind crossover study comparing AMIE to primary care physicians (PCPs) during text-based consultations with validated patient-actors, AMIE demonstrated superior performance in diagnostic accuracy and outperformed PCPs on 30 out of 32 evaluation axes according to specialist physicians and 25 out of 26 axes according to patient-actors. Note that a text-chat interface was unfamiliar to the PCPs for remote consultation, so the study should not be regarded as representative of usual practice in (tele)medicine.
Read paper | Nature

2. Diagnostic Conversation. A state-aware framework that enables multimodal LLMs to conduct diagnostic conversations, strategically requesting, interpreting, and reasoning about the medical data needed for diagnosis.
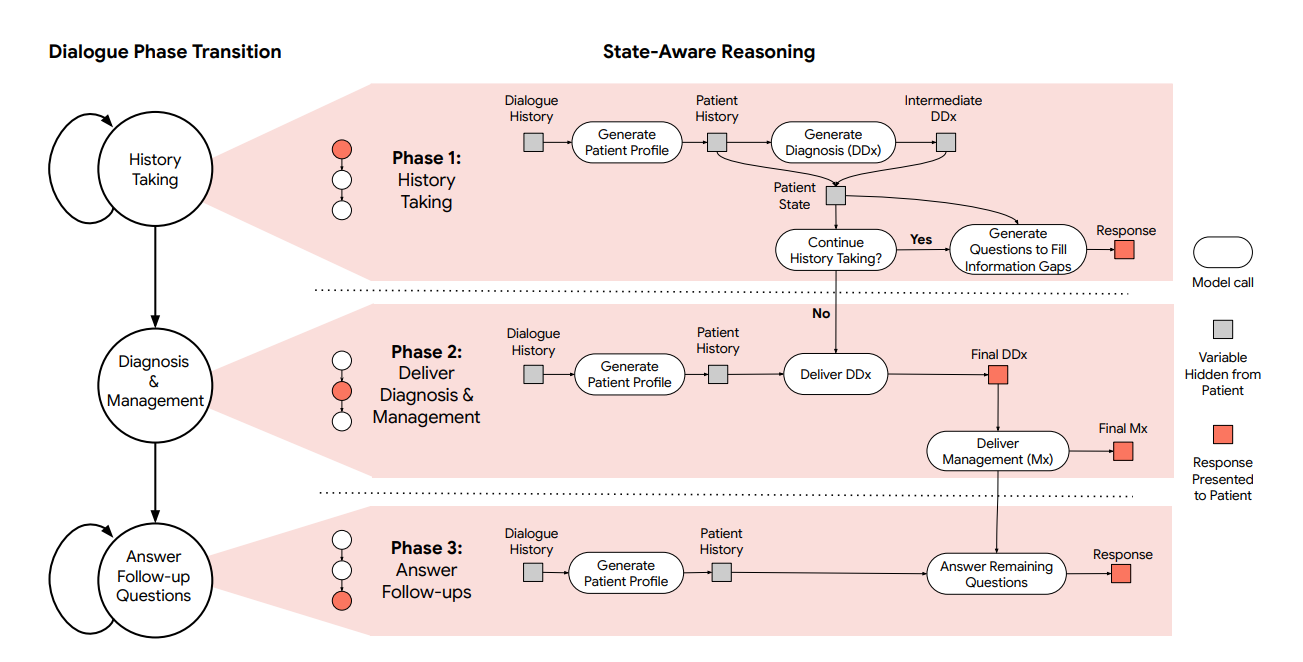
Saab et al. developed a state-aware dialogue framework for LLMs that dynamically guides conversations through structured phases of history-taking, diagnosis, and management, strategically requesting and analyzing multimodal data (such as skin photos, ECG tracings, and clinical documents) based on evolving patient states and diagnostic uncertainty. This framework allows them to enhance a general-purpose LLM, Gemini 2.0 Flash, with a domain-specific inference-time reasoning strategy without fine-tuning. The system progresses through three distinct phases, each with a specific goal: (1) history taking (gathering comprehensive patient information), (2) differential diagnosis (DDx) & management (formulating and presenting DDx and management plan), and (3) answer follow-up questions (addressing remaining concerns). Within each phase, the system maintains an internal state. This state guides specific actions, such as asking targeted questions, requesting multimodal data, generating internal summaries/DDx, or providing explanations. Transitions between phases are triggered automatically when the system assesses that the objectives of the current phase (e.g., sufficient information gathered, DDx presented) have been met, based on its internal state evaluation. In a randomized, double-blind study of chat-based consultations with patient actors simulating 105 evaluation scenarios, this system’s performance matched or surpassed that of primary care physicians across crucial clinical dimensions.
Read Paper | arXiv
3. Differential Diagnosis. Developing a comprehensive differential diagnosis is fundamental to quality medical care, requiring physicians to synthesize clinical history, physical examination findings, and diagnostic test results through an iterative reasoning process. Could large language models, with their interactive capabilities, effectively assist clinicians in generating more accurate and comprehensive differential diagnoses?
McDuff et al. evaluated the ability of AMIE (Articulate Medical Intelligence Explorer) to generate differential diagnoses alone or as an aid to clinicians. Using 302 challenging real-world case reports from the New England Journal of Medicine clinicopathological conference, twenty clinicians were randomized to receive assistance from search engines and standard medical resources such as UpToDate and PubMed, or assistance from AMIE in addition to these tools. Clinicians and AMIE generated lists of possible diagnoses for the cases, and AMIE exhibited standalone performance that exceeded that of unassisted clinicians (top-10 accuracy 59.1% versus 33.6%, P = 0.04). Comparing the two assisted study arms, the differential diagnosis quality score was higher for clinicians assisted by AMIE (top-10 accuracy 51.7%) compared with clinicians without its assistance (36.1%; McNemar's test: 45.7, P < 0.01) and clinicians with search (44.4%; McNemar's test: 4.75, P = 0.03). Further, clinicians with AMIE assistance arrived at more comprehensive differential lists than those without. The use of AMIE did not add inefficiency or increase the time spent solving each case compared with search or other conventional resources. This suggests that the conversational interface was unobtrusive and intuitive. However, these cases represent 'diagnostic puzzles' rather than real-world examples of common clinical workflows, and it is therefore important to consider more realistic settings in which LLMs might prove of practical value in medicine.
Read Paper | Nature
4. Opportunistic Screening. Coronary artery calcium (CAC) scoring via ECG-gated CT scans effectively predicts cardiovascular risk, but most routine chest CTs aren't ECG-gated. AI could enable opportunistic CAC screening—deriving CAC scores in existing non-cardiac scans without requiring additional imaging—to identify at-risk patients who might benefit from preventive treatment.
Hagopian et al. developed a transformer-based U-Net variant that segments CAC on noncontrast, nongated CT scans and produces Agatston scores (a standardized method for quantifying CAC) based on the area and density of the detected calcium. Using imaging data from 98 VA medical centers across the United States, they showed that the AI-derived CAC can predict long-term outcomes in both symptomatic and asymptomatic patients. This predictive ability was generalized to 48 medical centers not present in the training dataset. When tested on 795 patients with paired ECG-gated scans, nongated AI-CAC achieved 89.4% accuracy for differentiating 0 vs. >0 and 87.3% for <100 vs. ≥100 Agatston scores, while being predictive of 10-year mortality and cardiovascular events. At present, VA imaging systems contain millions of nongated chest CT scans, but less than 50,000 gated studies. This asymmetry represents an opportunity for AI-CAC to leverage routinely collected nongated scans for cardiovascular risk evaluation.
Read Paper | NEJM AI
-- Emma Chen, Pranav Rajpurkar & Eric Topol