


Week 248
Note Generation, Language Modeling for Tabular Data, Virtual Cell, LLM-Based Agents, Causal Analysis
We are moving our newsletter to Substack for a better experience!
In Week #248 of the Doctor Penguin newsletter, the following papers caught our attention:
1. Note Generation. Handoffs, where patient information is exchanged between health professionals during a transfer of clinical responsibility, have been identified as a critical source of medical errors. Emergency medicine (EM) to inpatient (IP) handoffs are particularly challenging due to medical complexity, diagnostic uncertainty, rapidly evolving care plans, and time constraints, with suboptimal handoffs linked to adverse events. Could large language models (LLMs) help generate useful and safe notes for these critical EM-to-IP transitions?
Hartman et al. evaluated an EM handoff note generation system at NewYork-Presbyterian/Weill Cornell Medical Center, analyzing 1600 patient records from 2023. Their pipeline combined RoBERTa for saliency selection (to reduce context length), Llama-2 7B with LoRA fine-tuning for summarization, and rule-based pattern matching for structured data extraction. The system produces templated handoff notes containing both structured (labs, vitals) and unstructured (summarized clinical narrative) content. While the LLM-generated notes outperformed physician-written ones on automated metrics, they scored slightly lower in physician evaluations of usefulness (4.04 vs 4.36 out of 5) and patient safety (4.06 vs 4.50 out of 5). Though no LLM-generated notes posed critical safety risks, approximately 10% had potential for significant but non-life-threatening safety issues, suggesting the importance of physician review in the workflow. Given the absence of a current written standard of care in EM, such an LLM-based system could represent a transformative advancement in EM-to-IP transitions of care.
Read paper | JAMA Network Open
2. Language Modeling for Tabular Data. Spreadsheet-style data is commonly used in healthcare applications. Yet, despite the potential impacts of transferable foundation models for tabular data, the prevailing paradigm is still to train single-task models (e.g., XGboost) using a fixed schema on data from the same distribution on which the model will be deployed.
Gardner et al. developed TABULA-8B, a language model for tabular prediction, by fine-tuning Llama 3-8B on a dataset containing over 2.1B rows from 4M unique tables. The model processes tabular data through a structured serialization scheme that converts rows into text prompts with three components: a) Prefix: "Predict the value of <target_column_name>" followed by possible label values "val1||val2||val3||" b) Features: All key-value pairs from the row (e.g., "The date is 2015-03-22. The precipitation is 1.0...") c) Suffix: Question prompt with possible labels again ("What is the value of <target_column_name>? val1||val2||val3||"). A key innovation is the row-causal tabular masking scheme, which creates a causal attention structure where rows can only attend to themselves and previous rows from the same table, preventing information leakage between tables while enabling efficient training and preserving few-shot learning capabilities. The model was evaluated on 329 datasets from five major tabular benchmarks, including tasks like heart disease classification and diabetes prediction. TABULA-8B demonstrated zero-shot accuracy on unseen tables with over 15 percentage points higher than random guessing, a feat that is not possible with existing state-of-the-art tabular prediction models (e.g. XGBoost, TabPFN). In the few-shot setting (1-32 shots), without any fine-tuning on the target datasets, TABULA-8B is 5-15 percentage points more accurate than XGBoost and TabPFN models that are explicitly trained on equal, or even up to 16× more data.
Read Paper | NeurIPS 2024
3. Virtual Cell. Every cell is a dynamic and adaptive system where complex behaviors emerge from countless molecular interactions operating across multiple scales of time and space. While traditional cell models rely on predefined rules and mechanistic assumptions fitted to experimental data, recent breakthroughs in AI and omics technologies have opened up the possibility of developing AI virtual cells (AIVCs).
In this Perspective, Bunne et al. introduce a comprehensive framework for implementing AIVCs that could transform biomedical research. The proposed AIVC architecture consists of two key components: a universal representation system that captures biological states across scales (from molecules to tissues) and "virtual instruments" - neural networks that can manipulate and decode these representations. This learned simulator could model cellular systems under various conditions, including differentiation states, disease states, and environmental perturbations. The authors envision diverse applications: in drug discovery, AIVCs could enable virtual screening of therapeutic interventions while accounting for patient-specific contexts; in personalized medicine, they could serve as "digital twins" that track individual patient health and predict adverse events; and in basic research, they could revolutionize the scientific process by actively suggesting hypotheses and guiding experiment design. Despite several critical challenges, the authors argue that recent advances in AI and omics technologies make this an opportune moment to pursue AIVCs through collaborative efforts across academia, industry, and philanthropy.
Read Paper | Cell

4. LLM-Based Agents. LLMs are currently limited by the recency, validity, and breadth of their training data, and their outputs are dependent on prompt quality. They also lack persistent memory due to their intrinsically limited context window, which leads to difficulties in maintaining continuity across longer interactions or across sessions. This limitation, in turn, leads to challenges in providing personalized responses based on past interactions.
In this Comment, Qiu et al. discuss the opportunities of LLM-based agentic systems in healthcare as one solution to the limitations noted above. LLM-based agentic systems expand beyond traditional LLMs by incorporating three key external modules: a perception module for multimodal input processing, a memory module using vector-embedding databases for long-term storage, and an action module that can execute API calls and enable agent communication. These systems retain the original capabilities of LLMs while fostering new capabilities. The authors discuss four key healthcare opportunities: clinical workflow automation (potentially reducing administrative burden by 47%), development of more trustworthy medical AI through an autonomous verify-rectify-verify process that cross-checks outputs against external sources, multi-agent-aided diagnosis mirroring multidisciplinary medical teams, and creation of comprehensive health digital twins. However, the article also acknowledges significant challenges, including safety concerns, potential biases, over-reliance risks, and the need for robust regulatory frameworks, as the additional layer of complexity that agentic systems represent will pose further regulatory challenges.
Read Paper | Nature Machine Intelligence
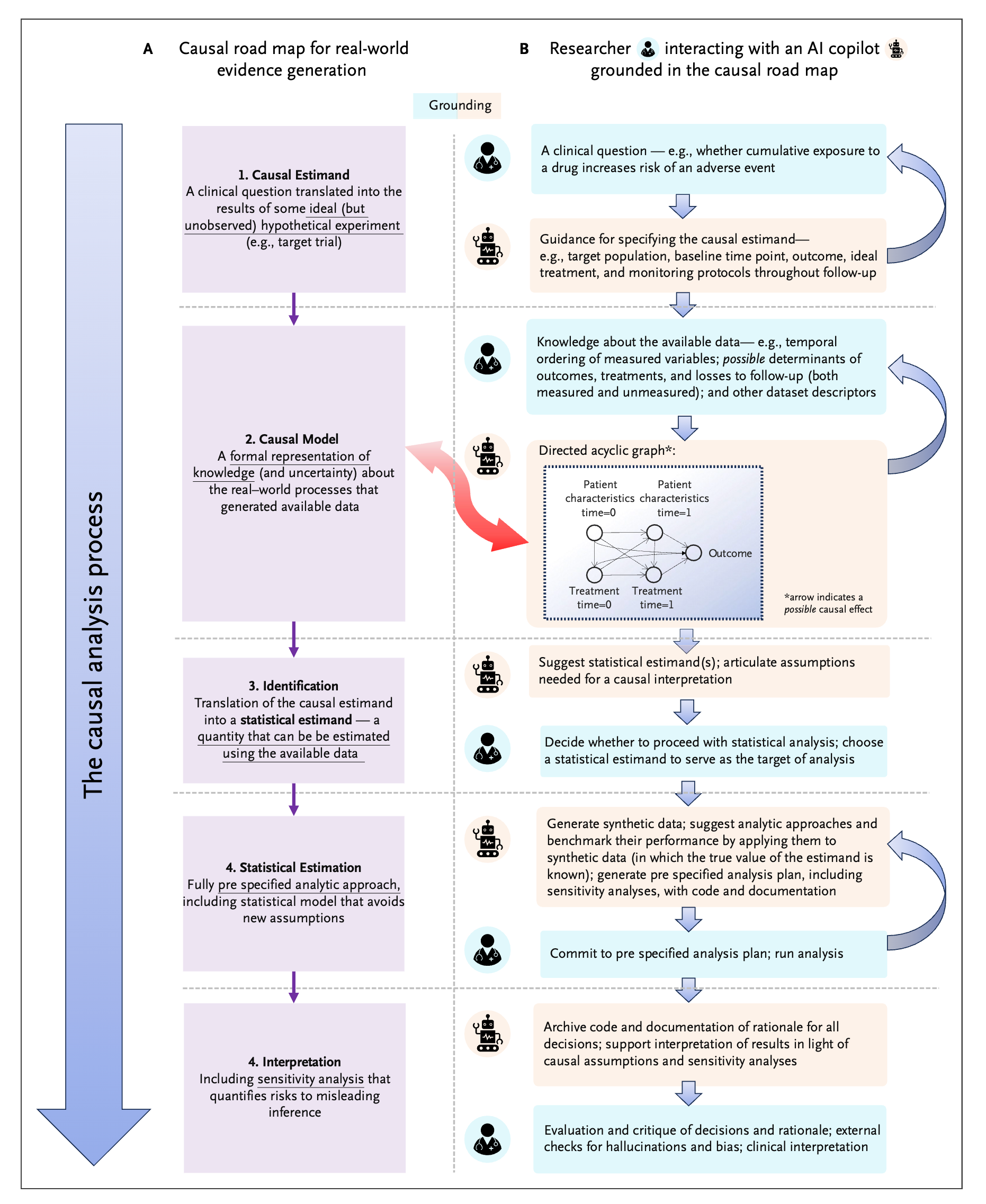
5. Causal Analysis. While there is growing consensus that real-world data should complement randomized trials in healthcare decision-making, current approaches to analyzing such data are complex, require diverse expertise, and are prone to errors.
In this Perspective, Petersen et al. propose the development of an AI-based "copilot" system to help researchers conduct high-quality causal analyses using real-world healthcare data. An AI copilot, grounded in a step-by-step causal road map, could assist researchers through four key stages: 1) translating clinical questions into well-defined causal "estimands" that specify parameters like target population and treatment protocols, 2) developing causal models using directed acyclic graphs (DAGs) to represent how variables like patient characteristics, treatments, and outcomes relate over time, 3) identifying and implementing appropriate statistical methods that can actually measure the desired causal relationships in available data, and 4) supporting careful interpretation through systematic analysis and sensitivity testing. Rather than replacing human reasoning, this copilot would augment research teams by making the process more systematic, transparent, and reproducible while helping to avoid common pitfalls in causal analysis.
Read Paper | NEJM AI
-- Emma Chen, Pranav Rajpurkar & Eric Topol