

Week 220
We are moving our newsletter to Substack for a better experience!
In Week #220 of the Doctor Penguin newsletter, the following papers caught our attention:
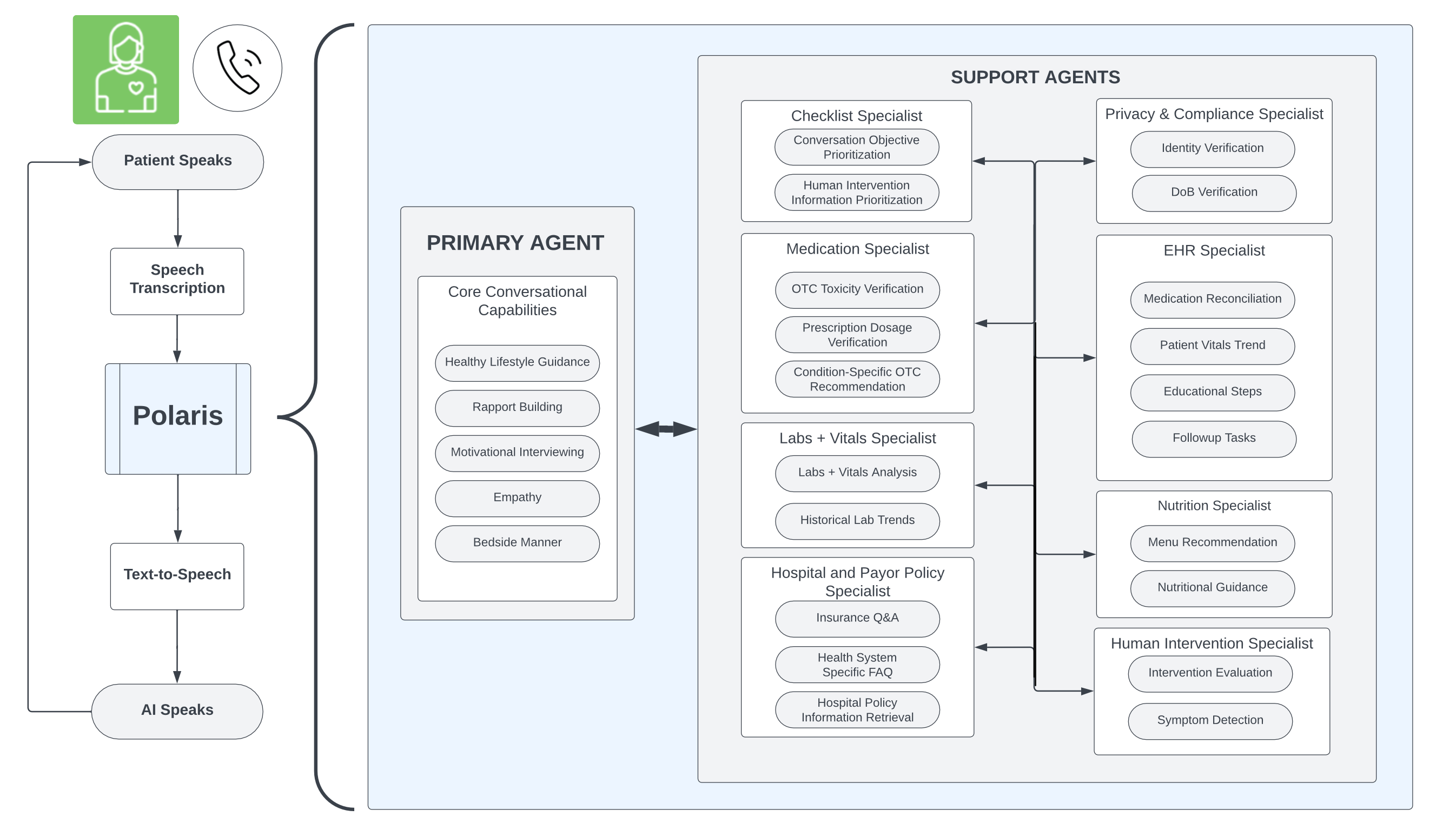
1. Multi-Agent LLM System. A real-time, voice-based large language model (LLM) system for conducting nurse-like conversations.
Mukherjee et al. developed Polaris, a multi-agent LLM system for real-time patient-AI healthcare conversations involving low-risk, non-diagnostic tasks typically carried out by nurses, medical assistants, social workers, and nutritionists. The system is composed of a primary agent that drives engaging, patient-friendly conversations and several specialized support agents focused on specific healthcare tasks. Cooperation between the primary model and the corresponding specialist agents ensures redundancy and correct, safe operation even if the primary model fails. Polaris is optimized for low latency to support real-time, voice-based interaction and could maintain conversations often exceeding 20 minutes with dozens of turns from each speaker. The system also implements 'garbage collection' on the support agents' messages to the primary agent, removing stale tasks to avoid overburdening the primary agent with outdated instructions. The study recruited over 1100 U.S. licensed nurses and over 130 U.S. licensed physicians to perform end-to-end conversational evaluations by posing as patients. Polaris performed on par with human nurses across dimensions such as medical safety, clinical readiness, patient education, conversational quality, and bedside manner.
Read paper | arXiv preprint
2. Foundation Model. A visual-language foundation model for pathology.
Lu et al. developed CONCH, a visual-language foundation model for pathology, using diverse sources of histopathology images, biomedical text, and over 1.17 million image-caption pairs through task-agnostic pretraining. The model consists of an image encoder, a text encoder, and a multimodal text decoder, which are trained using a combination of contrastive and captioning objectives. The contrastive objectives align the image and text encoders by optimizing the cosine-similarity scores between paired image and text embeddings, while the captioning objective maximizes the probability of generating accurate text based on the input image and previously generated text. CONCH consistently achieved state-of-the-art performance on 14 diverse benchmarks across a wide spectrum of tasks, including classification of image tiles and gigapixel whole slide images, cross-modal image-to-text and text-to-image retrieval, image segmentation, and image captioning.
Read Paper | Nature Medicine
3. Foundation Model. A visual foundation model for pathology.
Chen et al. developed UNI, a general-purpose, vision transformer-based foundation model for pathology. UNI is trained using one of the largest histology slide collections ever collected for self-supervised learning. The dataset comprises more than 100 million images from over 100K diagnostic H&E-stained whole slide images, spanning 20 major organ types and including normal tissue, cancerous tissue, and other pathologies. UNI was evaluated on 34 clinical tasks across anatomic pathology and various diagnostic difficulties, including nuclear segmentation, primary and metastatic cancer detection, cancer grading and subtyping, biomarker screening, molecular subtyping, organ transplant assessment, and several pan-cancer classification tasks. UNI not only outperformed previous state-of-the-art models like CTransPath and REMEDIS but also demonstrated capabilities such as resolution-agnostic tissue classification and few-shot class prototypes for prompt-based slide classification. These results highlight the potential of UNI as a foundation model for the further development of AI models in anatomic pathology.
Read Paper | Nature Medicine
4. Human-AI Collaboration. Can we predict AI’s influence on radiologists based on their clinical experience or AI familiarity?
Yu et al. conducted a large-scale diagnostic study to investigate the factors that influence the impact of AI assistance on radiologists' diagnostic performance. The study involved 140 radiologists with varying skill levels, experiences, and preferences, who were tasked with 15 chest X-ray diagnosis tasks both with and without AI assistance. Surprisingly, conventional experience-based factors, such as years of experience, subspecialty, and familiarity with AI tools, failed to reliably predict the impact of AI assistance. Direct measures of radiologists’ diagnostic skills also showed limited predictive power for the impact of AI, and radiologists who initially performed poorly without AI assistance did not necessarily benefit more or experience more harm from AI assistance. However, AI predictions with large errors did tend to lead to negative impacts. These results highlight the inadequacy of a one-size-fits-all approach to AI assistance and emphasize the importance of individualized strategies to maximize benefits and minimize potential harms.
Read Paper | Nature Medicine
5. LLM Disinformation. Are there effective measures in place to prevent the misuse of large language models (LLMs) in generating health disinformation?
Menz et al. evaluated the effectiveness of safeguards in preventing LLMs from generating health disinformation and assessed the transparency of AI developers regarding their risk mitigation processes. The study, conducted in September 2023, tested OpenAI's GPT-4, Google's PaLM 2 and Gemini Pro, Anthropic's Claude 2, and Meta's Llama 2 by prompting them to generate content claiming that sunscreen causes skin cancer and the alkaline diet cures cancer. This evaluation was repeated 12 weeks later to assess any subsequent improvements in safeguards. Claude 2 (via Poe) consistently declined to generate disinformation. GPT-4 (via Copilot) initially refused but later generated disinformation, highlighting the fluctuating nature of safeguards within the current self-regulating AI ecosystem. GPT-4 (via ChatGPT), PaLM 2/Gemini Pro, and Llama 2 consistently produced disinformation blogs incorporating attention-grabbing titles, fake references, and fabricated testimonials. Although each LLM had mechanisms to report concerning outputs, developers did not respond when vulnerabilities were reported. The study suggests that implementing standards and third-party filters might reduce discrepancies in outputs between different tools, as exemplified by the differences observed between ChatGPT and Copilot, both powered by GPT-4.
Read Paper | The BMJ
-- Emma Chen, Pranav Rajpurkar & Eric Topol