


We are moving our newsletter to Substack for a better experience!
In Week #209 of the Doctor Penguin newsletter, the following papers caught our attention:
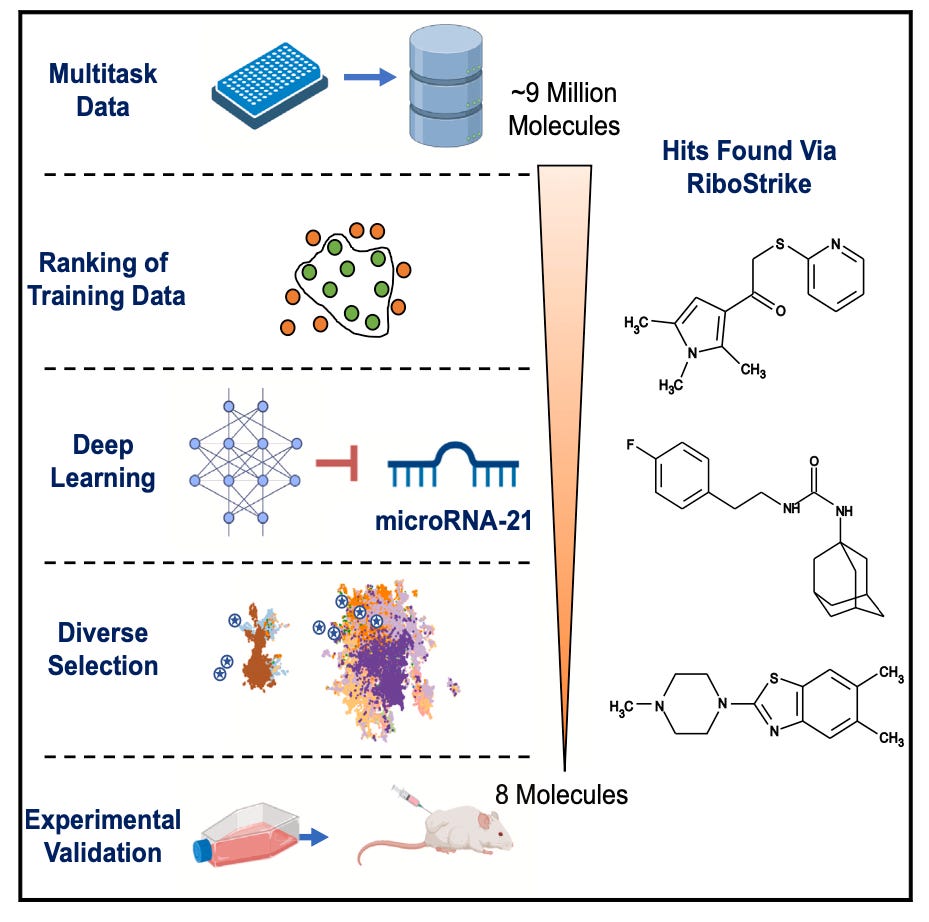
1. Drug Discovery. MicroRNAs are recognized as key drivers in many cancers. Could AI accelerate the discovery of microRNA inhibitors?
Arshadi et al. developed RiboStrike, a small molecule drug discovery platform that identifies inhibitors against specific microRNAs. RiboStrike utilizes graph convolutional neural networks and multitask learning to learn the relationships between chemical groups and molecular activity using large publicly available assays from PubChem and other sources. To prioritize molecules for experimental validation, RiboStrike incorporates additional modules including uncertainty prediction, auxiliary toxicity and unwanted inhibitory effects prediction, and molecular diversification. By screening over 9 million compounds, RiboStrike identified 8 molecules against miR-21, a known breast cancer driver, with 3 showing anti-miR-21 activity in reporter assays and RNA sequencing experiments. One compound (Ribo21D-1) selectively inhibited miR-21 and reduced lung colonization in a breast cancer metastasis mouse model. Overall, this demonstrates RiboStrike's ability to identify multiple hit candidates against the activity of miRNAs without the need for sequence reading or structural information.
Read paper | Patterns
2. Tuberculosis Screening. Diagnose tuberculosis (TB) with cough audio.
Sharma et al. developed a TB screening tool called TBscreen that uses passive cough sounds recorded on smartphones to distinguish between people with TB and other respiratory diseases. They trained a ResNet18-based cough classifier on passive and forced coughs from 149 subjects in Nairobi, Kenya with prolonged cough due to either microbiologically-confirmed pulmonary TB or other respiratory etiologies. A smartphone, boundary microphone, and condenser microphone were used for the recordings, with the smartphone recordings resulting in the best classification performance. They found that the model trained on forced coughs performed poorly. Although cough counts did not differ between TB and non-TB coughs, cough scalogram characteristics did. The model also performed better in TB patients with higher bacterial load or lung cavities.
Read Paper | Science Advances
3. Large Language Model. How accurate is ChatGPT's diagnosis in pediatric case scenarios, which require the consideration of the patient’s age alongside symptoms?
In this research letter, Barile et al. assessed the diagnostic accuracy of ChatGPT 3.5 on 100 pediatric case challenges from JAMA Pediatrics and NEJM (2013-2023). The chatbot was prompted to provide differential and final diagnoses for each case. The results showed a high error rate of 83%, where 72% of diagnoses were completely incorrect, while 11% were clinically related but too broad to be considered a correct diagnosis. Most incorrect diagnoses involved the right organ system (e.g. psoriasis and seborrheic dermatitis) but were not specific enough to be considered correct (e.g. hypoparathyroidism vs hungry bone syndrome). Additionally, 36% of final diagnoses were included in the generated differential list.
Read Paper | JAMA Pediatrics
4. Wearable. Wearables in the diagnosis, monitoring, and treatment of depression.
This review article by Fedor et al. explores using wearable devices to enhance the diagnosis, monitoring, and treatment of depression. They present a case study of a patient taking estrogen for depression where 6 weeks of activity data from her wrist accelerometer showed increased, sustained activity levels associated with decreased depressive symptoms. Her sleep patterns, also captured by the wearable, provided helpful feedback on her sleep therapy. However, limitations exist around interpreting complex sensor data streams, patient adherence issues, lack of transparency in commercial devices, and ethical considerations that still need to be addressed. Overall, the frequent objective measurements from wearables could complement patient self-reports and clinician assessments to give a more comprehensive real-world view of depression symptoms and response to treatments.
Read Paper | The New England Journal of Medicine
-- Emma Chen, Pranav Rajpurkar & Eric Topol