
Week 204
Pathology, Foundation Model, Large Language Model, Seizure Recurrence, Asthma Monitoring
We are moving our newsletter to Substack for a better experience!
In Week #204 of the Doctor Penguin newsletter, the following papers caught our attention:
1. Pathology. Pathologists grade the microscopic appearance of breast tissue using the Nottingham criteria, which are qualitative and do not account for noncancerous elements within the tumor microenvironment.
Amgad et al. developed the Histologic Prognostic Signature (HiPS), a comprehensive and interpretable score for assessing breast cancer survival risk incurred by breast tumor microenvironment morphology. To determine a HiPS score, a deep learning model was used to segment tissue regions and nuclei in each H&E-stained slide, followed by computational extraction of interpretable morphologic features. These features include stromal, immune, and spatial interaction features not included in Nottingham grading. The most prognostic features within each biological theme were selected and combined with ER, PR and HER2 status to fit a Cox regression model for cancer-specific survival. Derived from a prospective cohort of breast cancer patients across hundreds of US healthcare facilities, HiPS is a strong, independent predictor of survival outcomes in nonmetastatic ER+ and HER2+ cancers. It also consistently outperformed pathologist grading, driven by its stromal and immune features. Overall, HiPS is a robustly validated biomarker to support pathologists and improve breast cancer prognosis.
Read paper | Nature Medicine
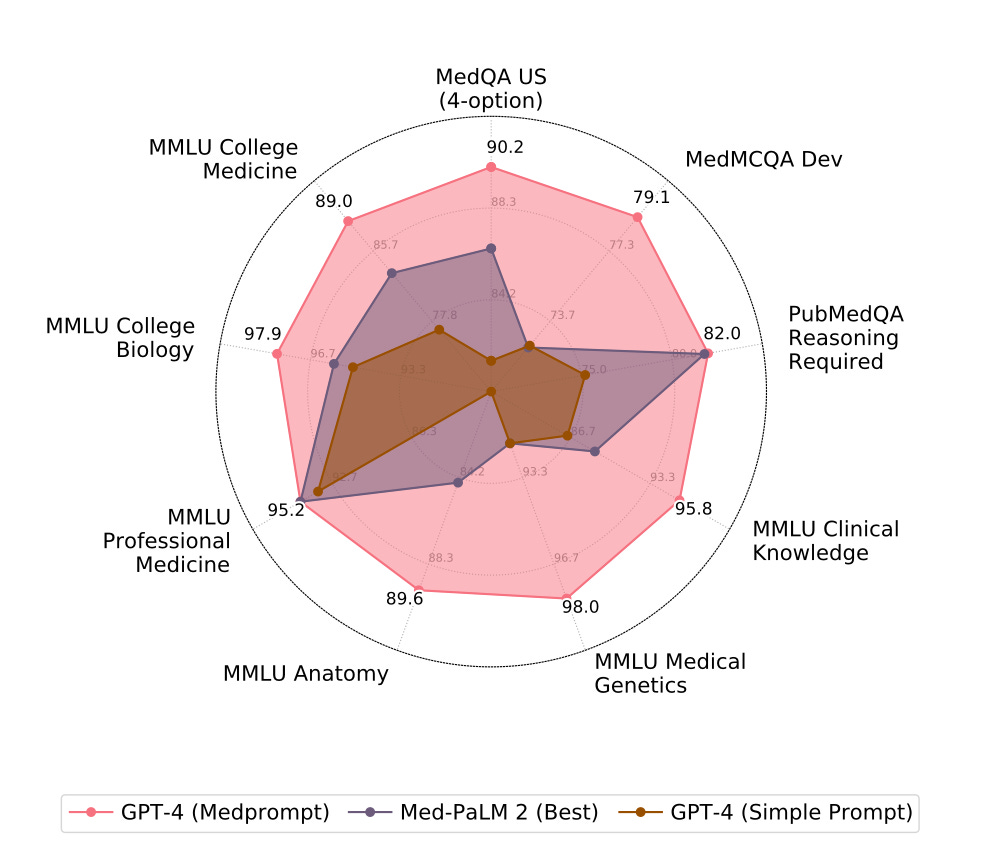
2. Foundation Model. Can modern Generalist foundation models outperform specialist models finetuned on specialty knowledge?
Nori et al. developed a domain-agnostic prompting strategy called Medprompt that unlocks deeper specialist capabilities in GPT-4. Steering GPT-4 with Medprompt achieves state-of-the-art results on all nine benchmark datasets in the MultiMedQA suite. It outperforms state-of-the-art specialist models like Med-PaLM 2 by a large margin, using an order of magnitude fewer calls to the model (5 API calls for Medprompt vs up to 44 calls for Med-PaLM 2). On the key MedQA dataset (USMLE exam questions), GPT-4 with Medprompt reduces the error rate by 27% compared to the best methods achieved with specialist models, surpassing 90% accuracy for the first time. Medprompt combines intelligent few-shot example selection, self-generated chain-of-thought steps, and a majority vote ensemble to yield a general-purpose prompt engineering strategy. This means Medprompt can readily apply to domains other than medicine.
Read Paper | arXiv preprint
3. Large Language Model. Open-source large language models (LLMs) in the medical domain.
Chen et al. developed and released MEDITRON, a suite of open-source large language models with 7 billion and 70 billion parameters that are adapted for the medical domain through continued pretraining on curated medical data. The models build on Llama-2 and are pretrained on a comprehensive corpus of PubMed articles, abstracts, and internationally-recognized medical guidelines. Evaluations on major benchmarks show that MEDITRON outperforms current state-of-the-art open-source models before and after task-specific finetuning. Compared to closed-source LLMs, MEDITRON-70B outperforms GPT-3.5 and Med-PaLM and is within 5% of GPT-4 and 10% of Med-PaLM-2. The models and the code to curate the medical pretraining corpus are released to the public.
Read Paper | arXiv preprint
4. Seizure Recurrence. Clinical orders and even the timing of these orders have been shown to hold substantial information about patient risk. Does data collected naturally as part of routine care, and not specifically for predicting seizures, hold signals that could predict the risk of seizure recurrence?
Beaulieu-Jones et al. pre-trained Large Language Models (LLMs) on clinical notes from patients diagnosed with epilepsy or convulsions. They then fine-tuned the models to predict seizure recurrence risk after an initial seizure-like event in children. Tested on over 14K patients from Boston Children's Hospital and over 15K patients from the IBM MarketScan database, the LLM accurately predicted seizure recurrence risk in patients with an initial seizure-like event using only routine clinical notes. These notes included neurology notes and communications (e.g., messages to patients and messages describing interactions with patients), EEG reports, brain MRI reports, head CT reports, discharge summaries, and other relevant notes. This study shows that, at a minimum, physicians capture and record a substantial amount of information in the form of clinical notes that can be useful for predicting seizure recurrence in children.
Read Paper | The Lancet Digital Health
5. Asthma Monitoring. Fast detection and confirmation of an exacerbation is crucial for asthma patients. Current medical guidelines recommend evaluating exacerbations in children under 5 years old based on parents' subjective assessment of the child's condition.
After investigating the utility of an AI-aided home stethoscope for monitoring asthma exacerbations in 149 patients (90 children, 59 adults) over 6 months, Emeryk et al. found that the subjective assessments by parents were insufficient to reliably confirm or exclude exacerbations in children. Instead, combining data from AI’s recognition of wheezes, rhonchi, and crackles in respiratory sounds, along with survey responses, peak expiratory flow (when possible), and oxygen saturation, allows highly accurate identification of exacerbations. They also show that the wheeze and rhonchi intensity detected by the stethoscope are the best single-parameter predictors of exacerbations in young and older children. Overall, this study highlights the value of AI-aided stethoscopes in providing objective data for asthma monitoring, especially among young children.
Read Paper | Annals of Family Medicine
-- Emma Chen, Pranav Rajpurkar & Eric Topol