
Week 198
Radiology Report Generation, Personalized Uncertainty, AI Adoption, Large Language Model
We are moving our newsletter to Substack for a better experience!
In Week #198 of the Doctor Penguin newsletter, the following papers caught our attention:
1. Radiology Report Generation. Timely interpretation of diagnostic imaging is critical to clinical decision-making for otherwise undifferentiated patients in the emergency department (ED). However, some EDs have to rely on preliminary resident interpretations or teleradiology services during off-hours, resulting in discrepancies in radiology reporting.
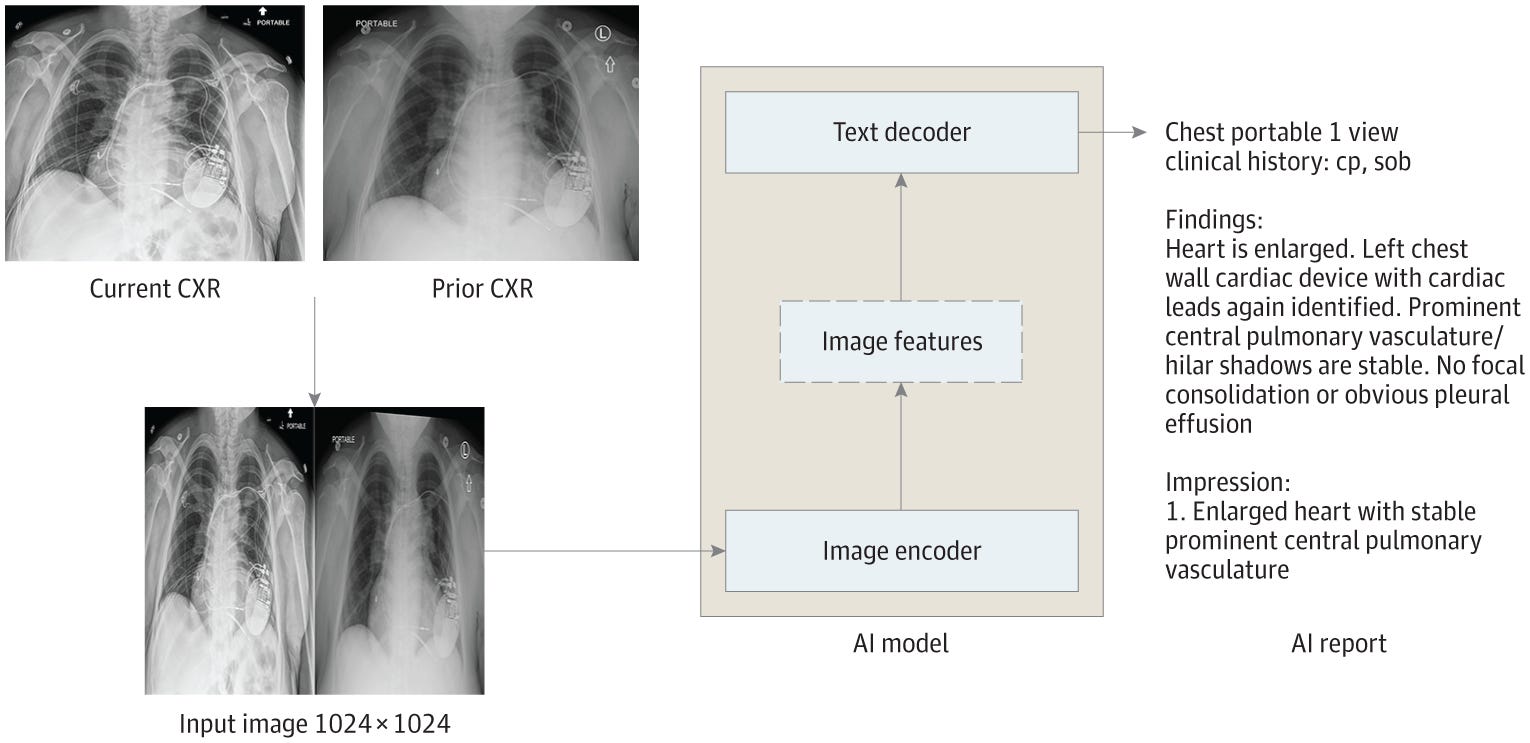
Huang et al. conducted the first study to assess reports entirely produced by generative AI from chest radiographs in a clinical setting. They collected 500 chest radiographs from patients in an ED without overnight in-house radiology services, where teleradiology is routinely used for all overnight imaging. The generated reports demonstrated similar clinical accuracy and textual quality to in-house radiology reports, while providing higher textual quality than teleradiology reports. Since the AI model was trained on institutional data, the generated reports followed institutionally standardized structured formatting, which enforces reporting on relevant aspects of the chest radiograph even in the absence of abnormalities, whereas teleradiology reports often omitted mention of support devices or pertinent negative findings.
Read paper | JAMA Network Open
2. Personalized Uncertainty. AI tools are often optimized to maximize population-level accuracy, which is less meaningful for individual patients due to individual differences.
Banerji et al. advocate for the use of personalized uncertainty in medical AI, which can be provided through conformal prediction. Instead of predicting a single most likely outcome for a patient, this method provides a shortlist of the most plausible diagnoses, with a certain percentage of certainty that the true diagnosis is included. The shortlist is determined by comparing predictions for a new patient to previous predictions for similar patients with known outcomes. If the model is unsure or inaccurate in its confidence, the list will be longer, signaling to the clinician that more information is required to pinpoint the correct diagnosis and treatment. Conversely, if the model exhibits reliable, evidence-based confidence, the list will be short, giving the clinician increased trust in an accurate diagnosis. Clinicians can decide the certainty level based on the severity and immediacy of the clinical situation, so serious conditions are appropriately presented even if less likely. By doing this, conformal prediction shifts the focus from the AI model trying to find one accurate recommendation, to offering the clinician personalized possibilities to investigate further.
Read Paper | Nature Medicine
3. AI Adoption. What is Radiology’s AI Adoption Dilemma?
In this Viewpoint, Jha discussed the structure of radiology and the incentives for radiologists to understand what hinders AI adoption in radiology. He argues that AI as a productivity-enhancing tool is unappealing to radiologists, and the efficiency gains might result in fewer radiologists working more efficiently but just as intensely. On the other hand, with both AI and radiologists checking each other's work, AI as a diagnostic aide may not reduce the net labor conscripted to extract meaningful clinical information from images. Jha suggests that radiologists should relinquish some of their work to algorithms and imagine new roles to harness AI’s full potential. For example, in lung cancer screening, the radiologist's job will shift from reporting as many CT results as rapidly as possible to coordinating screening, leaving AI to seek lung nodules.
Read Paper | JAMA
4. Recent studies in Large Language Models
Levkovich and Elyoseph compared evaluations of depressive episodes and suggested treatment protocols generated by ChatGPT-3 & 4 with the recommendations of primary care physicians. They found the models’ therapeutic recommendations aligned well with accepted guidelines for managing mild and severe depression, without showing the gender or socioeconomic biases observed among primary care physicians.
Read Levkovich & Elyoseph | Family Medicine and Community Health
Decker et al. compared informed consent documents for 6 common surgical procedures generated by surgeons to those generated by ChatGPT-3.5, finding the chatbot-generated consents more readable, complete, and accurate.
Read Decker et al. | JAMA Network Open
Goodman et al. evaluated GPT-3.5 and GPT-4’s responses to 284 medical questions generated by 33 physicians across 17 specialties. They found the responses to be largely accurate and comprehensive, although there were multiple surprisingly incorrect answers.
Read Goodman et al. | JAMA Network Open
Brin et al. evaluated GPT-3.5 and GPT-’s soft skills (communication skills, ethics, empathy, and professionalism) using 80 USMLE-style questions. The models demonstrated the potential to display empathetic responses.
Read Brin et al. | Scientific Reports
-- Emma Chen, Pranav Rajpurkar & Eric Topol